
DeepSeek's new model slashes AI inference costs
DeepSeek has just dropped something interesting: a new experimental model, the V3.2-exp, that they say could seriously cut down on inference costs. I mean, who doesn't want to save money, right? Especially when we're talking about the hefty server costs of running AI models.
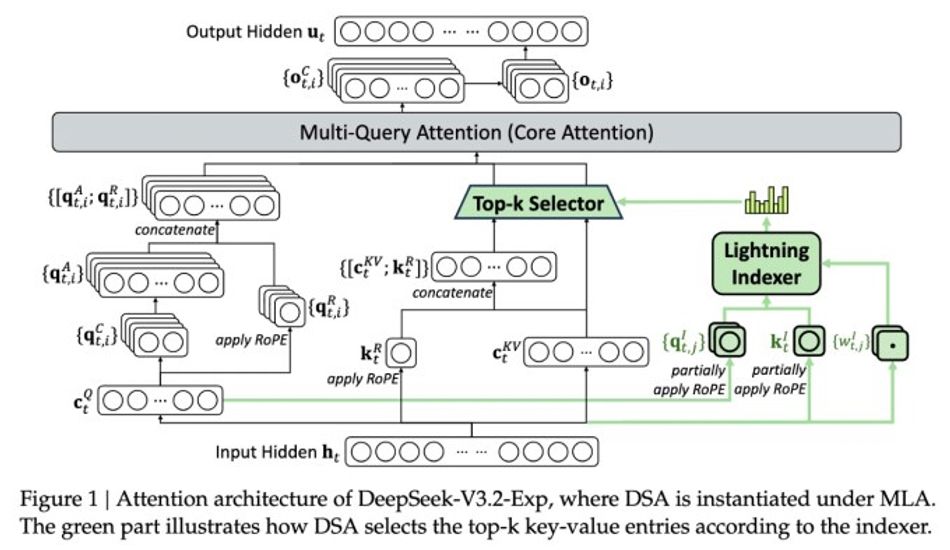
The real magic behind this model is something they're calling DeepSeek Sparse Attention. Now, I won't bore you with all the technical details, but the gist of it is that it's designed to prioritize the most important parts of the context window. Think of it like this: imagine reading a long book but only focusing on the key paragraphs that drive the story forward. That's essentially what this system does, which allows it to handle long contexts without bogging down the server.
What's genuinely exciting is the potential cost savings. DeepSeek's preliminary tests suggest that a simple API call could be up to half the price in long-context situations. That's a big deal! Of course, we'll need more testing to confirm these claims, but the fact that the model is open-weight and available on Hugging Face means that independent researchers can jump in and give it a whirl.
It's interesting to see DeepSeek, a China-based company, continue to push the boundaries of AI efficiency. While their earlier R1 model didn't exactly spark a revolution, this new sparse attention approach could offer valuable insights into keeping inference costs in check. And let's be honest, that's something that benefits everyone in the AI space.
1 Image of DeepSeek V3.2-exp:
Source: TechCrunch